wxCatalogue v2
17 January 2020Back in 2017 when I started doing electronics projects I soon had problems keeping track of what I had ordered and where it was — as a result I ended up reordering stuff because I either could not find where I had put it, or simply forgot that components of a specific value were ones I already had. To help mitigate the problems I wrote wxCatalogue to keep track of things like order codes and where I had put stocks of components.
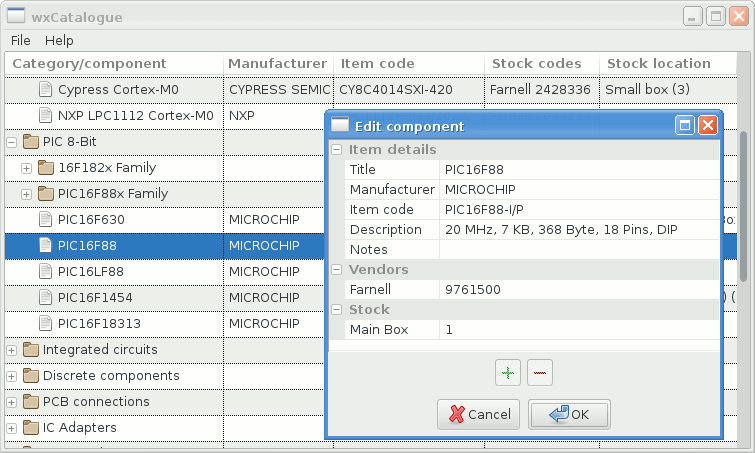
I finally got around to doing a complete reimplementation, which is the subject of this article. For this version there was a switch from Python to C++, using the latest wxWidgets rather than wxPython Phoenix, and the use SQLite rather than JSON as the back-end data-store. As with the previous version it is also available from my Bitbucket account.
The first version
During its development I never actually gave the original wxCatalogue version numbers and actual work on the program tailed off as bugs got fixed. Having not touched the code in about a year I decided to tag what was in the repository as v1.0 and then do a quick port to Python 3 that was tagged as v1.1 — the latter is because I correctly assumed the code would not be that difficult to port, and I had finally made the jump from Python 2 to Python 3.
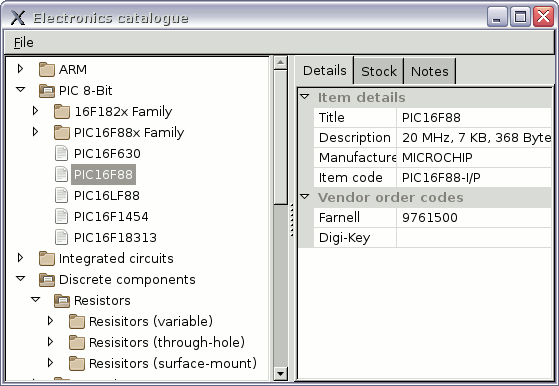
What worked out well
- Hierarchical classification
- From the outset I knew one of the biggest problems would be classifying components, and the basic approach of using a tree control worked well — with 398 components which were eventually split over 64 categories, I could not have realistically coped with coming up with a sane set of categories. The classification did break down a bit, most notably by having all the RF-related components kept in their own category rather than being classified logically with the rest, but the underlying approach was sound.
- Component titles
- Although I cut'n'pasted item descriptions from the invoices of orders, another smart move was having a seperate short title for display within the category/component tree, which was particularly nice for passive components such as capacitors and resisitors which needed sub-classifying based on size and form-factor. Keeping around the original vendor titles as a seperate description saved me on a few occasions I had screwed things up.
- Not trying to parameterise
- I had thought about having searchable numeric fields, most obviously for capacitances and resistances, but in the end decided the difficulty in how to make it generic was not worthwhile. Nesting of component categories achieved the same effect in a more general way.
- Stock location recording
- Due to limited space storage of components was mostly where they would fit, with grouping just as likley to be by date-of-order than anything more logical. As a result recording where I kept stock saved me a lot of hassle. It did not prevent the need to go searching, but in most cases it was a case of finding the named box and then only searching that one.
- The JSON data-structure
- Whereas the choice of using JSON for the main data-store may have been questionable, the way data was organised in the JSON file was spot-on. It was much more flexible than the user interface itself, and the ability to import a data-set into another was an important improvement I made.
Where things went wrong
- Stock level recording
- For a few items I did keep stock levels up-to-date, but this was limited to things like DIP and SOIC chips where the 5-10 units I typically kept aside were often depleted. Due to bulk-buying I have ample stock of most components, so trying to keep track is simple not worth the effort. It was only locations that mattered.
- Free-text stock values
- In the few instances where I gave stock non-numeric values it was things like “5 strips” and “1 pack” that were sufficently vague as to be of little value. They were also all things I would bulk-buy if they ever got close to depleted. I felt that the value domain needed tightening up.
- No searching functionality
- All too often I ended up opening the JSON file in a text editor and doing a manual search for things like stock codes. This became a problem when I had added a lot of components into the database following some big orders, but had yet to properly classify them.
- Alternative data presentations
- Although I did include command-line dumping of things like components ordered by storage location, it was a hack that I never used in practice. As a result I was never able to do any proper stock checking.
- Handling multiple vendors
- Farnell and Digi-Key were hard-coded as the two possible vendors, by giving each a seperate field within the component record, which by any measure is a nasty hack. This caused problems when I started getting a signficiant number of components from Mouser.
- Component notes
- I hardly ever used the component notes functionality, which in hindsight came down to not really knowing the extent the utility would be used. Looking at what few notes were recorded I cannot call it a bad feature though.
Implementation limitations
When I made the first version of wxCatalogue it was as much about getting back up to speed with Python and wxPython as creating a practical tool, so it involved many design and implementation decisions that in the long run limited its extendability. The one big one was storing data within the wxTreeCtrl that showed the category hierarchy, which initially simplified category management but at the same time made it difficult to do anything else with the data. Implementation of drag-and-drop rearranging of data was also a lot more involved than it should have been, needing entire sub-trees to be flattened then re-inserted.Ultimately the lack of seperation between the data and its presentation made it difficult to extend functionality, and the solution soon became apparent — replacement of the wxTreeCtrl with a wxDataViewCtrl that pulls the data out of an SQLite database. The choice of an SQLite back-end means that if I need to query the data-set in new ways, I can simply load it up in any SQLite front-end and use an SQL query, rather than needing to write custom code to trawl my data-structures.
User-interface design factors
Within the original wxCatalogue the disabling/enabling of the right-hand meta-data panels based on whether a category or component was selected left a lot of edge cases, which was a major motive for using a unified tree-control. In practice most of the time I used the utility was in order to see whether a component was one that I had previously stocked, and if so to find out either where the stock is stored or its order code. Therefore the main screen is dedicated to glancing these main data items quickly, and aside from rearranging the hierarchy and names of component categories all editing is delegated to dialogs. There were of course other concerns influencing the implementation:-- Dedicated component adding procedure
- A major reason why my use of the original version of wxCatalogue broke down was a back-log of orders building up, it was clear that a stream-lined way of bulk-adding new component records would be required. The add-then-edit approach used previously did not really work well in practice.
- Editing of components is rare
- Once added components and categories are rarely changed in practice, so while being able to edit component details is a requirement, it is not a target for fine-tuning. Delegating it to a dialog is intended to avoid all the edge-cases the first version had.
- Choice of controls for editing deta-data
- I was not sure which controls are actually the best for the purpose of editing component meta-data, so rather than reusing those from the component adding dialog I made a seperate dialog from scratch for editing existing component entries.
- No pop-up menus
- For at least the first iteration of this rewrite I decided to avoid pop-up menus completely. The use of pop-ups for adding and removing stock records within the original version was a bit of a hack, and everywhere else they were used there were alternative ways of getting at the same functionality.
- Keeping component order
- A major design goal is for the hierarchy defined by the user to dictate the order that things are listed, so this has to be explicitly recorded as part of the meta-data.
Data representation
The big change for version 2 is having the data within an SQLite database, so the starting point was coming up with database schema and queries, and then building the GUI around them. A major change to the modelling of data is much greater cross-referencing rather than everything being a property of a component — therefore manufacturers, vendors, and storage locations all now have their own tables within an SQLite database. The main motive here is to enforce consistency, which is most obviously important with storage locations because the latter is the one thing I would like an alternative grouping of components. What data is stored, as opposed to how it is structured, remained mostly unchanged though.Extra meta-data
I had thought about adding extra meta-data, but in the end decided to use just the parameters that existed within the original version of wxCatalogue. One idea was giving manufacturers alternative short identifiers — such asTI for Texas Instruments — but I felt this fell under feature creep rather than solving a prior identified problem. On the whole I was quite restrained, as adding in extra stuff at a whim is easy when writing a database schema, but hammering it into the GUI is a very different issue.
Maintaining category & component ordering
Since allowing exact placement of categories and components within the tree view is the single biggest selling-point of how the program presents itself, position meta-data needed to be explicitly recorded. From the outset it was obvious that using an explicit position variable was the way to do this, rather than letting SQLite queries order data in whatever arbitrary way it feels like. However while simple in theory in practice lots of edge-cases are thrown up — in short making sure no two entries at the same level end up having the same position value. A lot of the difficulty arose because things at the top-level used a NULL value for the parent identifier, and for some reason searching for a NULL value has to be done using anWHERE x IS NULL rather than having WHERE x=? and setting the corresponding parameter to NULL.
Stock count representations
After much thought I decided to restrict stock counts to integer numbers, because in the very few instances where a non-numeric value was actually useful, it should really have been put into the notes field. In the longer term once I do a proper stock-take I will likely only record actual values in cases where keeping track of exact item counts actually makes sense, which is a definite minority of components. Although the database allows this value to be null limitations with the GUI mean that -1 is used as a place-holder ‘no value’ — a minor irritation that I might try to work around in the future.Data importation
A major area of effort for this version of wxCatalogue was data importation, both from the JSON data-file format the previous version used, and the bulk adding of new data following component orders. Extracting data from online orders is something that I concluded will always be that bit messy, quite likely making use of make-shift hacks, so I decided it was best left to an external script rather than integrated into the main application code. In the end I decided the best thing was to extend the Python script I used for an initial conversion of JSON data into a more complete data import tool, as Python is a lot better than C++ for such tasks.Bulk record adding work-flow
Although I noticed early on that Farnell allows purchase records to be exported to CSV, I have found this facility to be problematic. Even at times it was not outright broken I felt that the item descriptions with the exported CSV were not as nice as those given either on the website account pages or within order confirmation emails. In practice I found that I got better results cut'n'pasting the order details into a text file, and then manually cleaning up the mess aided with a few GVim search & replace regular expressions. Partly as a result of things non-electronic related taking up my time over last summer, I built up a back-log of these that never got inserted into my data-file — one way or another an automated way of importing the text files that had accumulated would be required.Manufacturer name capitalisation
For reasons that I am unaware of manufacturer names are all upper-case on most cut'n'pastable order manifests, which is something I wanted to correct in an automated way for both my existing data and for new records. Looking at the names of manufacturers within my existing electronics data-set all words of two letters or less looked like they were supposed to be acronyms and hence should be all-uppercase, and words of five or more should only have the first letter capitalised, but with words of three and four letters things were mixed — NXP, Bel Fuse, FDTI, ROHM Semiconductor, and Alpha Wire. Ultimately I felt that classifying three letter or less as acronyms and four or more as words resulted in the least number of exceptions — there is provision for special-case substitutions but these are things I want to minimise.Needing wxWidgets 3.1.3
I get the impression thatwxDataViewCtrl et al have simply not received the attention they should have, and releases of wxWidgets prior to v3.1.3 lack functionality that are essential for wxCatalogue to work properly:
The github commit that bought the wxGTK implementation of wxDataViewModel::Cleared() in line with other platforms was pretty much the fix for a wxPython bug reported five years previously.
I felt that the effort in working around an essentually broken ability to get the control to reload from the data-model was not justifiable, so I decided to switch from Python to C++ and make wxWidgets v3.1.3 a requirement in order to get the fixed functionaity.
However there were still other problems that needed working around, which the next few sub-sections cover.
Drag'n'drop meta-data handling
The functions that are supposed to be used for transfer of information between the drag and drop events within a drag'n'drop of a data-view item are minimally documented if at all, and actual behaviour of the API is in many places at odds with what the documentation states. Defining a customwxDataFormat simply did not work so I resorted to using the stock wxTextDataObject and even then I have misgivings about how I ended up extracting the item data from this object — getting the data buffer pointer and reading it directly rather than getting a wxString object.
Drag'n'drop targeting
Although the data-view control visually differentiates between dropping an item between and in top of others, as shown in the two screenshot fragments below, the resulting events received by the application do not make any such distiction. I am at a loss as to whom thought it was a good idea to visually enable such distinction but not provide the information to the application itself. From what I have read this is likley due to the control being modelled on the Win32 tree view which does not have in-between dropping.
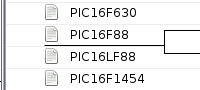

As a stop-gap hack the drop is processed as “on top” if the Ctrl-key is pressed and “above” otherwise — at some point I might try to drill down into the wxGTK code to get at the hover status, but in all honesty this is not something I ought to be getting my fingers dirty with.
Broken wxListView
Allegedly because of the underlying control on wxMSW thewxListCtrl widget only supports editing of the data in the first column. This is irritating as I wanted the first to be read-only and the second column editable — I had thought about simply swapping them around, but in the end opted to use
wxGrid instead. I suspect this line of thinking is one I went through previously, coming to the same conclusions with the original version.
Issues with wxGrid
ThewxGrid control is really a building block for spreadsheets rather than listing data, so using it for the latter is something of a square peg in a round hole. I had to add custom resizing code so that the columns were the correct width, and it still looks a bit ugly because flags to force the vertical scroll-bar to always appear are not honoured.
From Python to C++
Implementation of this new version of wxCatalogue was initially in Python, but since functionality I needed was only available in the latest wxWidgets and wxPython Phoenix still uses the older v3.0.x series, I abandoned the Python code at a relatively early stage and switched over to C++. I have a long standing love-hate relationship with C++, of which I have written about many times in the past, and is typified by appreciating things it has that straight C does not but then getting irritated with all the baggage that comes with the language. Professionally I no longer list C++ as a skill due to companies wanting Modern C++, and I cannot remember the last time I wrote a major program using C++ what was solving a problem rather than just experimentation. Having in the past opted for Python it is interesting how it compares to C++ for an identical program, although it is mostly a comparison of wxPython vs. wxWidgets than Python vs. C++.Header pit-falls
Although much of wxWidgets is included from a single header file, there are still several components that are delegated to their own header, which can trip you up coming from wxPython where everything is simply under the one name-space and imported en-masse. To be fair when wxWidgets first came out as wxWindows having to parse lots of header files was a significant overhead, whereas mass importing things in Python is not. It is also nowhere near as bad as Java which often has nested classes and to my knowledge no recursive import.Constant functions
In C & C++ explicitly specifying properties of variables allows the compiler to do very aggressive code optimisation, and the one most commonly used isconst which marks a variable as read-only. One variant of this I had not seen before is a const function — declared by having const clause in an unusual place as shown in the snippet below — where all class variables are treated as constant. Several of the functions of the wxDataViewModel class are declared as such, and it was by accident I found out the consequences.
unsigned int GetColumnCount() const { // ...
Obviously this was made to give compilers more leeway when it came to code optimisation, but it meant that the mapping of SQLite to wxDataViewItem had to be changed from on-the-fly in wxDataViewModel::GetChildren to a pre-processing step in wxDataViewModel::Cleared(). I am unsure whether wxPython just happens to be laxer or whether the v3.1.x series of wxWidgets tightened things up, but having to refactor the code while at the same time porting it was irritating. It took me a while before I finally worked out this was the cause of errors such as the following:
wxCatalogue.cpp: In member function 'virtual wxDataViewItem StockDataViewModel::GetParent(const wxDataViewItem&) const': wxCatalogue.cpp:283:53: error: passing 'const std::map<int, Entry*>' as 'this' argument discards qualifiers [-fpermissive] return wxDataViewItem(this->mapCategories[result]);
Extremely verbose errors
Although nowhere near as bad as I remember it being in the early-2000s, some C++ error message provide a lot of information that makes it hard to spot the important information: where the error actually is. A lot of things in C++ have some very fancy template-plumbing behind the scenes, and when there is a parse error with templates it is easy to get insanely verbose error messages. One not particularly contrived example of excess output was caused by keeping object pointers in a map, but rather than comparing the iterator to end() for some reason I compared a pointer to the object itself. The result is gcc getting seriously derailed and the errors go on for several screens.Mixing static and dynamic objects
I have historically found the way statically-allocated C++ objects operated to be a little odd, so in practice I always used dynamic allocation because it meant everything was pointer and I found pointers easy to understand. In contrast with static allocation things such as copy constructors, which also came with idiosyncratic notations, needed to be implemented. Due to its heritage wxWidgets almost exclusively uses dynamic allocation, though there are a few places where it instead uses static allocation. Switching between the two, something in the same line of code, easily causes confusion. Python treats everything as dynamic and sorts all memory allocation out for you.Standard C++ vs. wxString et al
Since wxWidgets was first released in 1992 whereas things likestd::string & std::vector only became part of standard C++ in 1998, and even then I think it was several years before they gained wide acceptance and support, wxWidgets includes its own equivalents such as wxString and wxArray. However even though the wxWidgets documentation recommends using the C++ standard classes I think the wxWidgets-specific ones are preferable — the interfaces are much more intuitive, and in the case of strings there is no proper equivalent of the wxString::Format(...) which is a printf-like string factory.
Defining an operator<<() function for classes provides a nice way for defining a string representation of a class, much like Python's __str__ and __repr__, but otherwise I find C++ strings and how they are tied in with I/O Streams to be a pain.
C++ “smart” pointers
Although wxWidgets requires most things to be dynamically allocated using the new operator, it has its own memory management system behind the scenes — as long as everything the application allocates is in some way properly associated with a parent control, such as being added to a sizer, they will be automatically cleared up when no longer needed. As a result pointer management and safty was not a major concern with this project. I have never in any case held the attempts by C++ to make pointers “safe” in high regard and what little reading into them I did this time round reinforced my views. To my knowledgeauto_ptr was introduced in the 2003 revision of the C++ standard, deprecated in favour of shared_ptr in 2011, and was removed in 2017 — this has ‘botched’ written all over it and is futher disincentive to even bother looking at them in detail.