wxCatalogue
20 October 2018This program is a little tool that helps keep track of the stock codes for all the electronic components I have bought over the last circa-18 months. Previously I just dumped the details into an ever-growing HTML file, which I occasionally tried to split into categories, but eventually concluded that I needed something a little more automated to keep track of what I had stocked. This program is the result — it is written in wxPython Classic and Python v2.7, for the simple reason that these are technologies I am reasonably familiar with, if a little rusty.
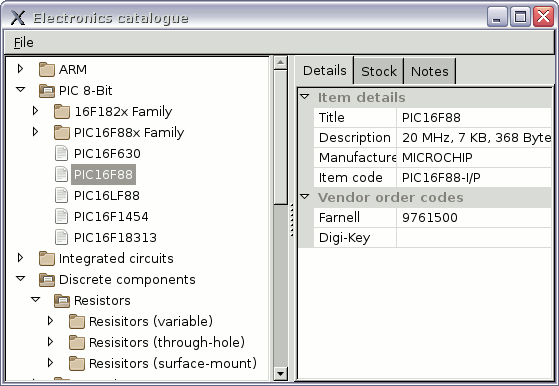
Background
A little utility, but one with a bigger story behind it. Back in 2011 when I was working for a neo-startup, one thing I often had to do was order in tools & components on an almost as-needed basis, and that often meant scouring many different vendor sites in order to source things. Procurement was never in my job description, and later on actual purchasing was delegated to someone else who was hired to handle the logistical side of the business, but there was one major project where I wrote practically the entire bill of materials used for project delivery. I nearly got stung by unexpected lead times once or twice, but nothing was ever missing. In hindsight my methods were rough-and-ready, and I cannot claim they were make-or-break for the company, but the diligence certainly avoided problems at a time the company was in difficult circumstances.
When I started doing electronics projects I was not even sure what a lot of the components I was looking for were even called — the best example is the 74HC238 which I now know is listed as a decoder, but when I first went looking for it I searched for terms such as parallel expander. In those early days I was ordering in so much stuff in a short period of time that just keeping track of terminology, let alone individual components, was far from trivial. For more obvious things like simple resistors or capacitors there are so many different ones out there — Farnell lists 130,000 different fixed-value resistors — that just finding one with the correct size and ratings takes a significant amount of time, which is not something one wants to go through again when restocking.
What is not explicitly mentioned in the two stories above, but particularly in the first one should be obvious, is stock management. A quick grep of the JSON data-file indicates that I have ordered 170 different items from Farnell alone, and I certainly have in the past ended up re-ordering items either because I could not locate them or I forgot I still had some stock left. Due to limited space it is not feasible for me to store things in a logical way that makes every item quick to find, but I can at least note down roughly where things are stored so I don't have to empty out every box to find the item I want. This is more critical for lesser-used items that are more likely to be buried deep.
wxWidgets
I first heard of wxWidgets back in 2000 when it was known as wxWindows, but the earliest personal use of it I can recall was LyteCFG back in 2009. I also used it for a prototype project in 2011 after having what I (perhaps unfairly) rearded as an unfavourable experience with GTK. Over the years it is basically the only cross-platform user interface toolkit I have taken any liking to, in part because it avoids all but the most basic features of C++ — other C++ toolkits seem to want a firmer grounding in more modern C++, often complete with complex template usage. As for Qt I simply don't want to mess around with either its licencing model or the custom build environment it seems to encourage projects to use.wxPython bindings
Compared to the underlying wxWidgets C++ API, wxPython is a bit of a mixed bag. The big plus is that Python hides much of the grubbiness that is inherent in C++, as well as doing away with some of wxWidgets's own idiosyncrasies that are in place because it adopted a pretty low common-denominator of C++. However a bit too often for comfort there is a need to refer to the C++ documentation, and then get stung because of small API differences due to differences between C++ and Python — for instancewxScrolledWindow::SetVirtualSize(int,int) is not implemented in wxPython due to lack of type-based overloading, so instead either the variant that takes a wx.Size object has to be used instead, or one has to guess that a tuple is also accepted. The wxPython documentation also does not mention that a tuple containing both the child and the enumeration cookie is returned by the TreeCtrl GerFirstChild() and GetNextChild() functions, although the wxWidgets C++ documentation itself mentions it as an aside.
wxPython releases
The standard version of wxPython is v3.0.2.0 which first shipped in November 2014, and this is the last release of what is now termed wxPython Classic — development since then has been on a new project called wxPython Phoenix which is supposedly a reimplementation on wxPython, but I have yet to work out whether it is actually blessed by the upstream wxWidgets project. Phoenix has explicitly not committed to strict backward compatibility, although they claim they will keep close to it, which given the history of Python2 vs. Python3 means that it will have difficulty getting wide acceptance. SlackBuilds carries v4.0.1 but from a quick check Fedora or Ubuntu only ship wxPython Classic. I am pretty sure wxPython Phoenix requires Python3, and this alone rules it out for me since I still use Python2 — a topic in itself that I will cover in the future.Data-management model
I decided to maintain the catalogue hierarchy entirely within theTreeCtrl, which on the whole was a good move as it avoided a whole host of synchronisation issues — the intrinsic information of a title and a list of child nodes is all the information needed for categorisation. In contrast synchronisation of data between the component objects and the right-hand detail area was one of the main source of bugs, with propagation of component title changes back to the object and then onwards to the tree node label a notable headache. Since tree nodes corresponding to components rather than categories required custom data to be attached in order to distinguish them, it made sense to instead collate all the component data in an object attached to the tree leaves.
Originally I planned to use an SQLite database, and this would have made the console-based listing modes I added at a late stage easier to implement, but when I started on the front-end out my main aim was to get a functioning GUI for sorting components into categories. My roughed-out database schemas were somewhat elaborate, allowing for arbitrary key-value pairs to be attached to each component on the fly, but with the GUI focus I decided to fit data storage around the GUI classes rather than the other way round. I decided I also wanted a text-based datafile, party because this was a first version and would likely want to edit the database by hand, and partly because I was expecting that I would be transferring the database between different computers a lot.
A major irritation with wx.TreeCtrl is that the only way to move a tree node — aside from some nasty hackery with a custom sort function — is to delete it and create a new one, which in turn means doing the same thing with all its children. Logistically this is not a major issue as the code needed to save and restore wx.TreeCtrl sub-branches into an external data-set was also needed for loading/saving the whole tree from/to a file, but it is a lot of overhead for the use-case of moving a node's positions among siblings without changing the parent node. I suspect this missing functionality is because wx.TreeCtrl was modelled after the Win32 API Tree View, which also does not have such a function.
Open-source development
Earlier in the year I shifted all my open-source projects onto Bitbucket, which included all but one of my previously closed-source projects, and of the latter some were projects that at one stage I considered “lost”. These days I am no longer sentimental about whether my personal projects are open- or closed-source, but I am well aware that stuff I prepare for publication tends to be better quality than stuff that I leave in my archives, as well as being a lot easier to relocate a few years down the line. In any case closed-source does not really make much sense for a language like Python. Although the repository was initially private this is the first personal project I have published that was on Bitbucket from day one, in part because I was doing development on both laptop and desktop systems. Using multiple systems when developing software is nothing new for me, but since there was never any doubt about the code being released, I decided that making every single commit public was logistically the easiest thing to do.Sorting out the database
One major side-benefit of writing a program to maintain my electronics catalogue, and it was entirely intentional, is the motivation to clean up my list of components. The original HTML file I used as my component list put things under approximate categories, and this was converted into a database using a make-shift script, but once in a database thing could be properly sorted and corrected. There was about a dozen duplicate entries, and a few with missing or wrong detail, but the main thing was that I got round to giving each entry a concise title as well as the detailed description that was mostly cut'n'pasted out of Farnell or Digi-Key. Having the tree view allows a nested categories three or four levels deep, with the intention that the leaf categories contain at most a dozen components, and that details such as through-hole vs. surface-mount are implicit in the category path. The original HTML file was clearly at the limit of maintainabilityKnowing what I had bought and having gone through it item-by-item meant that I could also have a proper stock audit — there were a few items I had plainly forgot I had bought, others I thought I still had stock but had run out, and even a few that I can only conclude got lost somehow. In any case having a better classification of the items together with a stock-take allowed for a better thought-out approach to storage, as well as a better focus of future projects on components I had already stockpiled — the latter point ever more important given that in relatively recent orders I have tended to bulk-buy if the unit-discount is more than 20%, regardless of actual likelihood of using up the stock. This is most notable with SMD resistors, where 1,000 costs only a Euro or so more than 100.